About a year and a half ago me and a bunch of bachelor students set out to interview 177 companies across 20 sectors that we found online who had developed agents to run workflows and published the results. Of course there is definitely a selection bias because, well, would you put your failure online? Indeed, but when we had built trust over time, also the skeletons came out of the closet and those were very interesting to research.
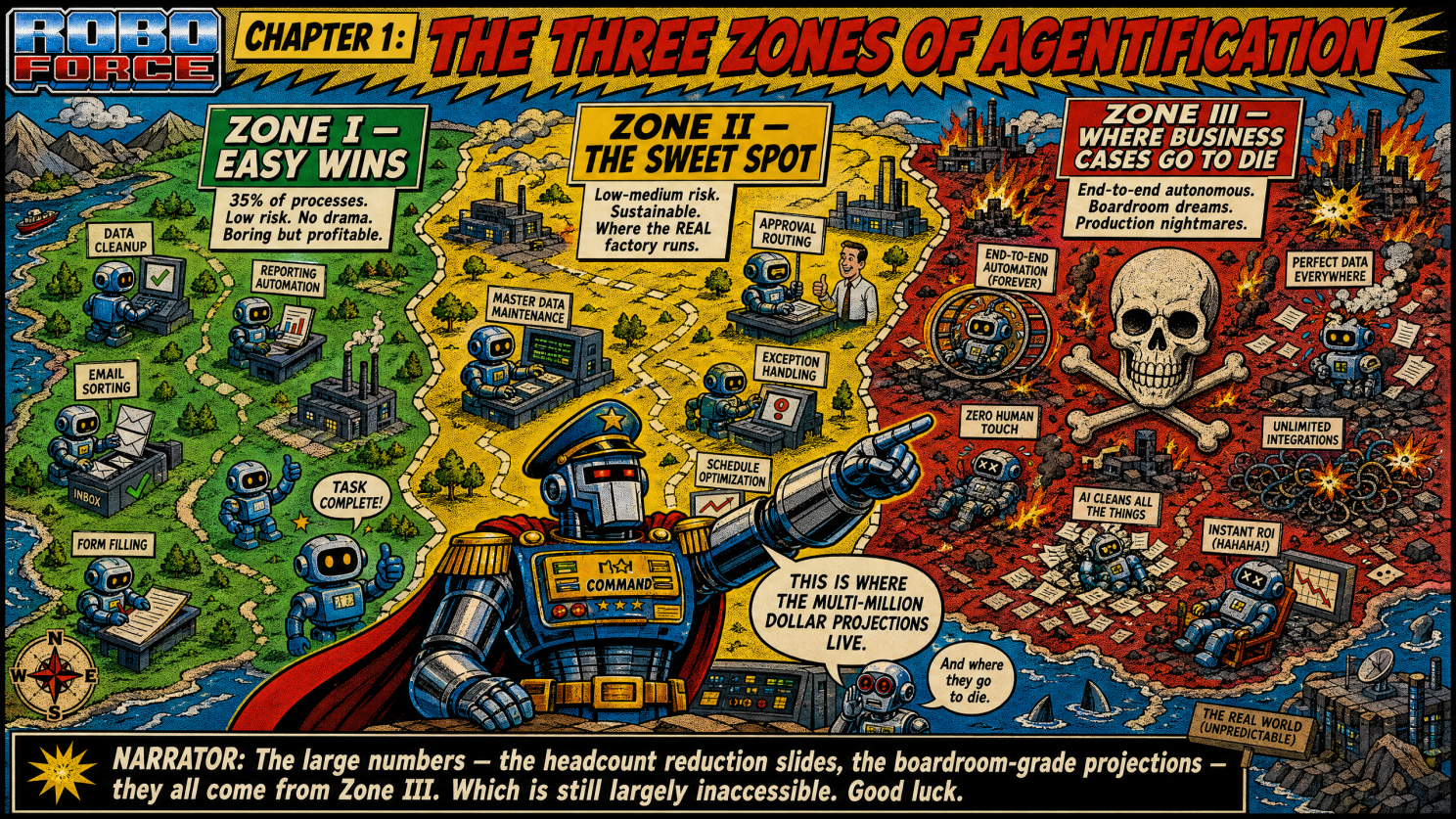
About 35% of processes were easily agentified, and we ended up calling them Zone I and II† type of processes and in our factory, we are focusing mainly on Zone II, because they are low-medium risk, don’t have lot’s of variations and edge cases, medium compliance requirements, and they are sustainable without a supervision army consuming the savings and therefore, they contribute to the business case because they free up lots of tedious tasks people would very much like to get rid off.

But the other processes – well, 73% of em anyway- hit walls. A third of cases were prematurely ended because their agents ran into data quality issues, and another third ran into governance issues. The latter is interesting because the thing was that it wasn’t compliant or anything like that, but simply because the cost of governance exceeded the savings‡
Remember this, because agentic ROI is fragile and lots of things can consume your margin before your eyes.
The business cases, however, are being built on Zone III, that is still largely inaccessible. The large numbers – I mean, the boardroom-grade projections – the headcount reduction slides, the multi-million-dollar transformation programs, they all come from end-to-end autonomous workflows (L2/3). Customer request enters the system, and completed outcome exits the other side without human involvement. But the problem is that end-to-end long-horizon multi-step agentic workflows break halfway through execution with a consistency that would be impressive if it were not also expensive.
And the thing is, that this isn’t a model intelligence problem. Current models are quite remarkable. They can reason (eats lots of tokens), plan, use tools and coordinate, but their problem is endurance – the ability to maintain coherent and reliable performance across fifteen, twenty, thirty, heck – even up to a hundred dependent steps in a production enterprise environment where your data is also inconsistent, the APIs are unreliable and the state diverges between systems.
What organizations are actually deploying, when you look behind the documentation that still uses the word “autonomous,” is a sequence of smaller bounded workflows, each one ending where the next one begins, separated by a Human-In-The-Loop checkpoint.
And yes, I am guilty as well too. It is simply because running long horizon workflows with agents is simply killing your ROI.

So yeah, when you chain together few-step human-bound workflows together, your end-to-end flow exists on paper, but in production it is a relay race where every baton exchange requires a knowledge worker standing at the track with a clipboard.
And that knowledge worker is not free.
In the deployments I tracked, Human-In-The-Loop supervision costs between fifty and seventy-five dollars per hour depending on geography, skill level, and if the person doing the reviewing has been adequately hydrated. Every review and exception queue or compliance check gets the meter running.
A workflow that executes ten thousand times per month and requires three minutes of human review per execution generates five hundred hours of labor per month. Five hundred hours at sixty dollars per hour, that is thirty thousand dollars per month in supervision costs for a workflow that was sold as reducing human labor costs.
The irony does not improve with familiarity.
But the supervision cost is a symptom. The underlying disease is the result of when you try to build the end-to-end workflow without the human checkpoints, and here the mathematics become genuinely unpleasant.
Let’s do a little al-jabr.
A reasonably capable agent making a single tool call or retrieval decision will fail somewhere between 2% and 5% of the time in real enterprise conditions because production environments are structurally adversarial since your APIs will time out or context windows fill with noise. Even on tightly controlled academic benchmarks, the best available models fail between 23% and 28% of bounded multi-step tasks, and enterprise processes are not bounded academic benchmarks. They are on average fifteen-step procurement workflows operating against live systems that someone in infrastructure last modified on a Friday afternoon before a public holiday.
Take a 98% per-step success rate, which is optimistic for a complex enterprise action involving tool calls, data retrieval, policy validation, and state updates across multiple systems. If a single step succeeds 98% of the time, then two dependent steps succeed together roughly 96% of the time. Five steps bring you to about 90%. Ten steps take you to 82%. And at step fifteen, the probability that every preceding step succeeded without contaminating the ones that followed is approximately 74%.
Roughly one out of four workflows has already failed before it finishes, and that calculation still assumes the failures are independent, which is the kind of assumption that only survives inside a spreadsheet that has never been shown to an infrastructure engineer.
That is the ugly truth of Zone III.
And to make things worse, on top of the compounding failure probability, add an agent that has entered a validation loop because a retrieved document contradicted an earlier retrieval, spending tokens and time re-examining the same information from slightly different angles. An then add context degradation as the workflow accumulates two hundred retrievals worth of competing signals and begins losing the thread of what it was originally trying to do, and top it all up with a tool failure that produced a partial success like updating Salesforce but timed out on SAP, so the customer now exists in one system but not the other, and every downstream workflow will treat both states as authoritative depending on which system it consults first.
None of these events are exotic, my smart friend.
In the 177 deployments we tracked over a little more than twelve months, governance emerged as the dominant constraint in agentification projects, with data quality issues contributing to most failures. The models were rarely the primary bottleneck, but what consumed the business case was the cost of managing the uncertainty that autonomous operation generates.
The real story of agentic AI is therefore not about intelligence.
It is about economics.
How much autonomy can be introduced before failure rates become unacceptable.
And how much human supervision remains necessary before the promised savings turn from black to red.
Everything else, like the architect’s benchmark results, the engineer’s context window sizes, the model’s reasoning improvements, and the vendor’s orchestration frameworks, is all secondary to the question of whether the workflow can be made to work economically in the environment where it actually needs to run.
This article is my attempt to answer that question honestly, which means covering the parts that conference presentations skip. In this piece I will cover the seven specific failure modes that appear so consistently across long-horizon agentic deployments that I just had to name them.
It is about why governance costs grow faster than most business cases model and what happens when agents begin optimizing against each other, why the economics of supervision are frequently worse than expected and what can be done about it and it ends with the conclusion that agentic AI ROI is fragile and that the balance between autonomy and control is more art than science at this stage, and that the organizations most likely to succeed are the ones that reduce every cost they can influence while accepting with clear eyes the costs they cannot.
If you build these systems, fund them, or are about to justify one in a steering committee presentation, read all of it. Especially the parts where I am describing a deployment that you will recognize.

‡ Read (3) How to build an agentification factory that actually turns a profit | LinkedIn
† Read (4) The real story behind enterprise scale process agentification | LinkedIn
More rants after the messages
Visit the ATLAS website. It’s free. I built it for myself. And now you can use it too.

- Connect with me on Linkedin 🙏
- Subscribe to TechTonic Shifts to get your daily dose of tech 📰
- Please comment, like or clap the article. Whatever you fancy.
The economics of a dream
A few years ago organizations were excited about chatbots. Then came copilots. Then came retrieval systems and AI assistants that could interact with documents, applications, and databases. Each generation expanded expectations and got folded into the next round of vendor promises and now all of those expectations have converged on one destination . . .
Agentic autonomy.
Not the task-level version, and certainly not the supervised variant where a human still reviews the output before anything consequential happens. I’m of course talking about full process-level autonomy, where a customer request enters one end of the system and a completed outcome emerges from the other, and the only human involvement is somebody checking a dashboard to confirm that the numbers are moving in the right direction.
The reason executives want this is not irrational. It is, in fact, extremely rational, which is part of what makes this whole situation so darn complicated. Labor costs is a significant share of most operational processes. A typical enterprise workflow contains hundreds of small decisions that individually appear trivial but collectively consume thousands of hours every year. Rules-based automation like RPA helped with some of this in the past, but rules-based systems fall apart the moment reality introduces variability, and reality introduces variability constantly. Customers provide incomplete information and your suppliers change requirements, regulations evolve or systems just return unexpected responses. But now Large Language Models changed this because, for the first time, software could handle ambiguity without requiring someone to write an explicit rule for every possible edge case.
The answer, and I want to be precise here because this distinction is what the entire article turns on, is that individual capability and workflow capability are not the same thing. A person can perform a single task brilliantly and fail entirely when asked to execute twenty dependent tasks in sequence.
Organizations understand this instinctively when dealing with humans, becuase nobody would promote someone to manage an entire business function simply because they are good at one part of it, but that same intuition evaporates when the subject is AI. The vendor shows an agent completing a task and the audience extrapolates. If it can do one thing, it can surely do ten. If it can do ten, it can do twenty, and, and, and . . . if it can do twenty, it can run a whole procurement process! or an onboarding workflow! or a claims pipeline! or a network provisioning operation! or a..! or a…!
You’ve been there, my friend, and now, you’re the one that has to deliver.

The formula one car pulled by horses
There is a pattern that I’ve seen happening in almost every agentic deployment I have observed, and it follows a trajectory that is so friggin’ consistent that I can now predict it within a few weeks of a team going to production. The first few weeks go well. Your agents complete their tasks, the metrics improve and the project team starts using words like “scaling phase” and “organizational adoption”. Then somebody begins preparing a conference presentation and the word “autonomous” appears in internal communications with an optimism that will later on become embarrassing.
Then the exceptions arrive. Oopsy.
A customer enters information the workflow wasn’t designed for, and your supplier changes a process or the API has changed and now returns an incomplete response that would have been obvious to anyone who had worked in the domain for more than a week. Then the workflow hesitates. Someone panics. And a human is inserted.
That insertion is of course described as temporary, but it is almost never temporary because within weeks there is a second review stage, then a compliance checkpoint, then an exception queue, then a manual approval requirement for decisions above a certain risk threshold. The governance diagram grows to three times its original size! But the documentation continues using words like “autonomous” and “intelligent” or “self-directed,” because the governance diagram is not the document that gets shown to the steering committee.
Gosh, if I just would’ve received a dollar each time this happened.

What actually exists in their production environment is a collection of smaller workflows separated by human intervention points. One agent completes a bounded task and a human reviews the result, then another agent performs the next activity and another human validates the outcome. So this way, the process advances through a sequence of controlled stages rather than one continuous chain of autonomous decision-making. The Formula one car, as it turns out, is being pulled by horses, but the car is still impressive to look at.
The interventions appear harmless individually, a two-minute review here, a three-minute validation there, a five-minute exception handling process that comes up twice a day, but the mathematics are less forgiving than the project plan. A workflow executing ten thousand times per month where each execution requires three minutes of human review translates into five hundred hours of labor, which translates into multiple full-time employees whose sole responsibility is preserving the reliability of a system originally designed to reduce dependence on employees.
Man, the irony is so dense it has its own gravitational field.
The workflow requires people because it is not sufficiently autonomous and organizations end up hiring people to protect the savings generated by removing people. Enterprise technology has always produced contradictions, but agentic AI appears to be making contradiction into a product feature.
Governance costs are particularly insidious because they hide.
Token costs appear on invoices and governance costs appear as review boards, with approval processes, compliance assessments, audit trails, risk evaluations, monitoring systems, and exception management procedures.
Death by a thousand successful decisions
One of the most persistent misconceptions in enterprise AI is that good decisions produce good outcomes, and the persistence of this misconception is impressive given how regularly it is contradicted by experience. The reason long-horizon agentic workflows violate this intuition is that every agentic action modifies the system state and an assumption shapes the next assumption.
The agentic workflow is constantly constructing the reality it must later navigate.
This is something to remember.
A pilot flying Amsterdam to New York who deviates by one degree during takeoff will not be noticed by the passengers, but several hours later, that same one-degree deviation has become hundreds of kilometers of separation between the intended destination and the actual destination. Nothing failed but nonetheless the trajectory drifted. And long-horizon workflows behave identically, except that nobody is looking at the map because the individual step metrics all look fine.
Just take a customer onboarding workflow. An agent retrieves customer information and the retrieval succeeds, then another agent validates addresses and that validation also succeeds, a third agent checks product eligibility, and that assessment succeeds, a fourth agent generates contractual documents, that document generation also succeeds and finally, a fifth agent schedules implementation activities and the scheduling is successful as well.
Every component behaves exactly as designed.
But the outcome was completely wrong because the customer information retrieved in the first step was six months out of date, and every subsequent decision inherited that flaw. Nobody failed individually, but the process failed because the workflow was internally consistent from beginning to end. The pilot still arrived at the wrong place.
Traditional governance frameworks evolved to evaluate actions because actions are visible -The action could be inspected and judged – agentic workflows create a different problem where the action is perfectly reasonable and every retrieval request returns a relevant document or runs a tool call or follows established policy and in the end, every action passes inspection but the workflow still moved toward the wrong destination, but the governance system continued generating green lights.

The seven horsemen
The horesemen do not typically arrive alone, heck, that would be almost reassuring, because a single failure mode is diagnosable and fixable, butr no, the seven horsemen arrive together and even reinforce each other. This, my smart friend, produces the exact operational situation that causes me to develop an interest in beekeeping. I will describe each one individually because they have individual characters, but understanding them as a system is what matters.

The first horseman | CONTEXT DEGRADATION
Every generation of enterprise AI eventually discovers, usually during the third month of a production deployment, that the workflow that worked beautifully in the controlled environment begins producing outputs that look increasingly, um, creative.
The model is usually not the problem, but the context is.
A model can only reason about the information which is available to it at that moment. When a workflow begins execution, the agent typically has a relatively clean understanding of the situation and the relationship between the problem and the desired outcome remains tractable.
Then the workflow continues.
New information arrives and tools generate outputs and agents exchange messages with each other and before long the workflow contains far more information than it possessed at the beginning, and most people assume this makes the workflow smarter. But in practice, it often makes the workflow confused in ways that look, from the outside, exactly like competence.
The challenge we are facing here is preserving relevance. Something that was important in step two of a fifteen-step workflow may still exist inside the context window but exerting almost no influence over decision-making, because it has been buried underneath everything that arrived between steps three and eleven. The signal does not disappear. It simply becomes diluted until it loses its ability to influence behavior†
Enterprise environments accelerate this problem because they are structurally noisy since they contain lots of customer records and historical transactions, support tickets, and of course regulatory requirements that all compete for contextual attention. Us humans have developed an intuitive understanding of which signals matter when, and we recognize inconsistencies but agentic systems are significantly more trusting. Give an agent three contradictory documents and it will attempt to reconcile all three.
So, as workflow length increases, contextual entropy increases, and retrieval quality declines, which deteriorates planning accuracy and that leads to a lower workflow quality. But the thing is that the workflow appears healthy throughout this process, but the trajectory is already compromised.
Context engineering is the discipline of deciding what information to include, and what to prioritize, and to an agentic program, this is more valuable than model selection for enterprise workflows. This sentence would have seemed strange two years ago and is now obvious to anyone who has actually built these systems at scale. A smaller model with excellent context management frequently outperforms a larger model with chaotic context.
And that, is commercially inconvenient for the vendors selling access to the largest possible models, which you don’t even wanted in the first place, because they cost you an arm and a leg.
† Read this short post on how I organized my Hermes memory into five distinct layers: https://www.linkedin.com/posts/marcovanhurne_thememoryarchitectureofanaiagentpptx-activity-7466394319323762688-4phr?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAAxzqYB4AwSHq5JL_9w3AU4LCPBOVQdgq8

The Second Horseman | MEMORY FRAGMENTATION
At some point during every serious enterprise AI project, someone discovers memory and feels briefly like they have found the solution to the first horseman. You add memory, but the workflow loses context, then you add more memory, but the workflow struggles to maintain continuity across long-running processes, then you scream, and in despair you add even more memory. This idea generates entire product categories full of vector databases, long-term memory systems, episodic memory stores, semantic memory layers, knowledge graphs, context engines, agent memory frameworks. New startups appear every few week in this domain and all are claiming to have finally solved the memory problem.
But memory is considerably more complicated than remembering things.
I walk into a room and forget why I went there at least twice a day. The problem is never that my brain deleted the information but the connection between the situation that triggered the thought and the memory that should surface in response got lost somewhere between the couch and the fridge. The retrieval failed. Agents working with memory systems fail in exactly the same way, but the scale is orders of magnitude larger, and somebody pays for it.
When information enters a memory system it is subject to retrieval mechanics (similarity scores, embeddings, ranking algorithms, search heuristics, metadata filters, relevance calculations, that sort of stuff). Every layer introduces another opportunity for the correct memory to lose a competition against a memory that merely looks relevant. Then, the workflow receives an answer which happens to be wrong. Now, most vendor demonstrations avoid this problem because they use carefully prepared data where the retrieval target is obvious and the answer lives exactly where the presenter expects it to live. But production environments contain twenty years dusty data with millions of records, and decades of operational procedures entered by people who expected nobody would ever need to retrieve them with any precision.
The library for the agent is so large, that the librarian becomes confused and the strange phenomenon that emerges is that retrieval difficulty increases, because more documents create more ambiguity, which increases the probability that the workflow receives information that is useless†
The assumption in multi-agent systems is that agents automatically share understanding because they share access to information.
But no.
Access is not understanding.
A planning agent and an execution agent may read the same document and arrive at different conclusions. The result is that understanding becomes distributed across multiple systems that never fully reconstruct the same picture of reality.
Human beings would call a meeting. Agentic systems call it orchestration.
Memory fragmentation is an alignment problem between stored knowledge and operational relevance, and once memory begins fragmenting, the workflow gradually loses its ability to distinguish between what it originally intended to do and what it is currently doing.
† This situation can also be solved by creating a layered memory, read: https://www.linkedin.com/posts/marcovanhurne_thememoryarchitectureofanaiagentpptx-activity-7466394319323762688-4phr?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAAxzqYB4AwSHq5JL_9w3AU4LCPBOVQdgq8

The third horseman | PLANNING DRIFT
If context degradation is the gradual loss of relevance and memory fragmentation is the gradual loss of continuity, then planning drift is the gradual loss of direction.
A plan is a hypothesis about the future, and the longer the time horizon over which the plan operates, the less reliable the cooperation becomes. Most agentic workflows begin by creating some form of plan and only then begin executing. The problem is that execution itself changes the environment. Every action the workflow takes modifies the world it must subsequently navigate.
Think about this for a second.
A customer updates information, and a supplier changes availability. . . that sort of stuff. The environment keeps moving, but the plan does not always notice, and this creates a paradox. An incompetent agent might fail early and visibly, which is actually somewhat useful because visible failures trigger investigation, but it also may successfully execute dozens of actions based on assumptions that ceased being valid an hour earlier, and progress indicators remain positive, everything looks healthy, but the entire trajectory is already wrong.
Most workflows are optimized to execute, but I am yet to see a workflow that is optimized to doubt. The ability to recognize when accumulated evidence should trigger a reassessment of the original plan is one of the capabilities that distinguishes experienced human practitioners from everyone else, and it is one of the capabilities that current agentic systems struggle most to replicate reliably.
The multi-agent version of this problem is particularly interesting. The question of who gets to change direction when the execution agent discovers something that invalidates the original plan, or when the monitoring agent detects a changing environment, or when the evaluation agent identifies an emerging risk, is not always clearly answered.
We, as humans, resolve these questions through leadership structures and escalation pathways, but agentic systems frequently lack equivalent mechanisms‡ .
‡ Check open source repos Paperclip and Polsia for agentic workflows that represent human organizational dynamics.

The fourth horseman | TOOL FAILURES
You now know that the first three horsemen operate inside the cognitive layer of the workflow and the result is that the workflow loses its grip on reality in ways that are difficult to observe until the consequences become visible because a customer will call you because you 500 coin instead of 450.
Now, the fourth horseman arrives from reality itself.
When an agent leaves its reasoning environment and then attempts to interact with the world, the agent runs into APIs, where elegant planning encounters infrastructure and when carefully constructed workflows discover that the vendor schema changed but no one flagged because it was technically backwards-compatible . . . in four out of five cases.
Agents are dependent creatures. And if you want it do do anything, it becomes dependent on external systems.
Traditional software has been managing these problems for decades with things like retries, circuit breakers, monitoring, recovery mechanisms or redundancy. These are entire disciplines built around the fact that infrastructure occasionally behaves weird, and your agentic workflows now inherit all of those problems and then add new ones, because a conventional application knows exactly which API call it intends to make, but an agent must first decide which tool to use, then determine how to use it, then execute the call, interpret the result and decide what to do next. Failure can occur at any of those stages.
The partial success scenario is when the genuine nightmares begin.
Say, an agent is responsible for customer onboarding and it retrieves customer information and then attempts to create records in three separate systems. The first and second API succeeds, but the third times out. Now, the customer exists in two systems but not the third. Future workflows encounter inconsistent records and different departments see different information. So, the agent tries again, and retries, and sometimes it can get stuck in a loop, sucking tokens until you stop it.
Suppose a workflow depends on ten external systems during execution. Each system offers 99% availability which is a number that your vendors print on their brochures. The workflow experiences the combined reliability of all dependencies. Ten systems with 99% availability produce a combined uptime of approximately 90% and every additional dependency creates another opportunity for failure or latency.

The fifth horseman | AGENT LOOPS
Every technology eventually develops its own pathology. Databases sometimes corrupt data, computer systems hit by a neutron flip a bit or networks generate packet storms and in most organizations I’ve worked, spreadsheets become critical business infrastructure despite the protests of every engineer in the building.
And agentic systems have loops.
The reason loops are dangerous is that they initially resemble intelligence. Human professionals double-check things, and so we think that agent loops imitate caution, but the difference is that humans eventually reach a conclusion yet the loop does not. I’ve found that research agents are particularly susceptible to this problem. The first search returns useful information and the second returns additional information, but then the third returns something contradictory. Then the agent decides more evidence is required and more evidence generates the need for more evidence and several thousand tokens later the agent is chasing it’s own tail like my Weiner. And when this happens in multi-agent systems, it looks like everybody is reviewing everyone else’s work and nothing actually ships.
There is also the execution loop, which is immediately expensive. An API call fails and the workflow retries, but then the retry fails, and so on. In traditional systems, retry storms have worsened outages for as long as distributed systems have existed. Agentic systems reproduce the behavior with enthusiasm and a far more richer vocabulary for justifying this behavior.

The Sixth Horseman | STATE INCONSISTENCY
Every compay likes to believe they have a single version of the truth bt then someone opens SAP and another opens the spreadsheet that Karen built in 2019, which somehow became a critical operational dependency when Karen left in 2021 and nobody has touched it since because everyone is afraid to break it.
Am I describing every finance department?
State inconsistencies arise when reality becomes fragmented across systems, and enterprise environments are essentially factories for producing this condition. Humans learn to navigate this through organizational folklore, like never to trust that report from Sam on Monday morning, and always verify supplier records manually, ignore the inventory numbers until the nightly sync completes. The knowledge is tribal and engrained in the collective memory of a department and it’s real and valuable.
Then agents inherit this environment without inheriting the folklore, and that creates a specific. category of problems. Let’s start with a customer onboarding workflow.
An agent retrieves customer information from CRM. Then a second agent checks contract status in another platform and another verifies billing information in a financial system. But the problem is that the three systems disagree because the customer changed their information yesterday, but only one system received the update, and two systems did not. The workflow now faces a question of which version of reality should it trust but it lacks the experiential intuition that would cause a human employee to recognize immediately that something feels wrong.
Now, you can do something about it.
The simplest thing that actually works is timestamp comparison. Before an agent trusts any record, the workflow checks when each source last received an update and flags discrepancies above a threshold instead of picking the most recent value. Then there’s a canonical source hierarchy, defined explicitly in the workflow design instead of letting the agent discover it at runtime. In the hierarchy, a CRM wins for identity, contract platform wins for entitlements and billing system wins for financial state, and any conflict between them triggers a hold. The one most teams skip because it requires admitting the workflow is not fully autonomous, is a lightweight human escalation path for exactly these conflicts. No, not a full review queue, but a targeted flag stating “these three records disagree, please look at this one thing”. That escalation costs thirty seconds of someone’s time, but letting the workflow pick the wrong version and propagate it through the next twelve steps costs considerably more.

The seventh horseman | HALLUCINATED ASSUMPTIONS
When most people hear the word hallucination in the context of AI, they imagine a model inventing facts. And yes, those failures exist but they are also not the hallucinations that create the largest operational damage in enterprise workflows (just a few percent).
The truly dangerous hallucinations are structural. They are assumptions.
A factual hallucination is relatively easy to detect because someone discovers an error, but with an assumption hallucination, the workflow encounters incomplete information like missing fields or a detail the customer forgot to provide. The workflow now faces a choice, stop and escalate – or infer.
Human beings are making this choice constantly and we manage it reasonably well because we generally know when we are guessing. but agents are less reliable in this regard. The workflow infers a value that appears to be reasonable and then, every subsequent action treats the assumption as established reality. The process is internally consistent, but its foundation is wrong.
This is why assumption hallucinations propagate so far without being detected. The workflow will never announce the assumption. It simply behaves as though the assumption are true. A missing supplier identifier turns into an estimated supplier identifier. That sort of thing. Or an ambiguous customer request becomes a precise one. No one notices until the workflow has generated contracts, or allocated resources at which point the cost of correction is not proportional to the size of the original assumption.

And in multi-agent systems this dynamic becomes worse when an agent creates an assumption and the rest inherits it. But the thing is that the assumption gains authority through repetition but traditional governance frameworks evaluate actions – was the policy followed, was the approval obtained, was the process executed correctly – and therefore the workflow can pass every check. The initial mistake takes seconds but the recovery process can consume weeks.
The solution to this is that the workflow needs to distinguish explicitly between verified information and inferred information at the moment the inference is made.
Yes. At inference time. Not post-hoc.
And you need a confidence score with a threshold below which a workflow stops and escalates. This sounds obvious, but it is never implemented because it requires someone to decide, in advance, how much uncertainty the business is willing to accept at each decision point. And that conversation people find uncomfortable, and execs can’t even grasp the question in the first place.
You also need to evaluate premises, and not only actions which the policy required. You need to add a lineage requirement, where any decision above a certain consequence threshold must me traceable to a verified source instead of an inferred one.
But in the end, all these measures do not eliminate assumption hallucinations, but the goal of this is to make them visibile so that you can recover quickly.
And this is why you need an evidence factory.

Governance is the hardest problem to tackle
Ok, no one gets excited about governance. Well, apart from Thierry Zedda that is. But other than him no one attends a conference hoping to hear about audit trails and watches keynote presentations waiting for a discussion of accountability frameworks. We all know that governance is the broccoli of enterprise technology, but at the same time we all know that it matters, but still we don’t want it on the menu. But the difference with a menu is that the brocolli stays on the side of the plate because you don’t touch it, but governance itself has a habit of consuming the main course, the dessert, and most of the wine budget.
In the 177 deployments we tracked, governance was the dominant constraint far more consistently than model capability. The organizations that initially worried about prompt quality found themselves, six months later, in having to have conversations about approval chains, risk ownership, escalation procedures, monitoring strategies, and audit requirements. The technical conversation had turned into a financial conversation.

The reason behind this makes sense when we view this through the lens of the seven horsemen since each horseman introduces uncertainty into the workflow and governance exists to manage uncertainty. And so, the more autonomous the workflow becomes, the more uncertainty it generates and that in turn requires more governance. But governance is costly at 50-75 Euro an hour, and therefore, the savings generated by automation begin competing directly against the costs required to make the automation safe.
This competition is where many business cases develop stress fractures that were not visible in the pilot environment. A workflow that saves $100,000 annually through labor reduction looks cool in a steering committee presentation, but after the monitoring requirement arrives, and the exception handling, then the compliance reviews, then the incident investigations, then the model evaluations, then the periodic audits, then the governance reporting, then the operational support structure. . .Pfff. . . After all of that, twenty thousand dollars disappears. Then another twenty thousand. Then another ten thousand. The automation still creates value, but your margin becomes thin enough to require renegotiation of the original ROI assumptions.
One of the more fascinating patterns in enterprise AI is the emergence of governance agents which are systems that are deployed specifically to supervise other systems. Things like Review, monitoring, validation and risk agents. You will find the architecture develops a supervisory layer. Then a supervisory layer for the supervisory layer. Then a human supervisor for the supervisory layer supervising the supervisory layer. And before you know it, you’ll end up in a bureaucracy that attempts to regulate itself, and the economics become increasingly strange, because every agent introduced to reduce labor eventually requires additional governance capacity to manage the uncertainty it creates.
And I’ve found that at some point, the relationship between agents and governance starts looking like taxation. Economic activity generates value. Governance extracts a percentage of that value in exchange for stability.
Something like that anyway.

The cost of watching the machines
At some point every agentic program comes to the conclusion you need people who watch the machines. These people have a background in the business of a particular process, and an apt for tech and AI. And they don’t come cheap. And then somebody opens a spreadsheet at the steering committee and then the room gets quiet.
The primary economic variable in agentic AI is the cost of supervision. Every autonomous workflow exists on a spectrum between complete freedom and complete control. Complete autonomy creates unacceptable risk whereas complete supervision eliminates the savings and your business case survives somewhere in between, and finding that point is considerably harder than most project plans suggest. As I said earlier, this part is more art than science and it grows with experience.
Therefore, never build your business case with a planning horizon shorter than eighteen months.
In mine, they’re usually between 2-3 years even.
And that is because the mathematics are unforgiving at scale. Say an agentic process operator (that is the name I came up with, not like ‘industry standard’) costs $60 per hour. A three-minute review per workflow execution appears harmless and so does a five-minute exception review, but running a workflow ten thousand times per month at three minutes of review per execution translates into five hundred hours of labor, and that translates into multiple full-time employees whose sole function is preserving the reliability of a system that was supposed to reduce the need for full-time employees.
Review agents appear to offer a solution. If humans are expensive, why don’t we use agents to supervise other agents. This works, partially, but it introduces its own costs. Of course there’s compute costs and maintenance costs, and eventually, someone must verify that the review agent is reviewing correctly. But the thing with this form of adversarial checking doesn’t eliminate errors altogether.
Let me tell you why.
I did some math a long time ago. And in it, I set out to calculate the minimum number of verification agents you need to eliminate uncertainty. The naive assumption is that adding more reviewers continuously improves reliability. If one checker misses an error 5% of the time, then surely five independent checkers must be dramatically safer. That assumption sounds reasonable until you realize that this independence is largely fictional and that is because they are trained on similar data sets and that tends to make similar mistakes, and if they are using similar retrieval systems, they tend to retrieve similar evidence, and if they are reasoning through similar architecture (because you were too lazy to introduce a separate validator model), they tend to converge toward similar conclusions! So, the major conclusion was that adding more reviewers increased the cost much faster than it decreases uncertainty. So, in the paper, I propose to abandon democratic verification and replace it with something called Bayesian evidence aggregation if you still want to go ahead with it.
I ran a test with a traditional five-agent majority-voting architecture, and that produced an undetected error rate of approximately 1.2%. The Bayesian mechanism reduced that figure to around 0.15% and at the same time it reduced the number of verification checks required through adaptive stopping mechanisms‡

But the thing is when you move toward long-horizon autonomous workflows, the more you see the cost of verification dominating the economics, and that realization brings us directly back to the central argument I’m trying to make in this article which is that the challenge is always managing uncertainty, and verification and governance can reduce those risks, but they can never eliminate them.
The trick is to balance your measures in such a way that you end up with a risk that matches a fully human operated workflow, but with less cost.
‡ If you want to know more about the method I used, visit Eigenvector/research and look for the SVE paper
The search for economic survival
The AI industry operates on a strategy that can be summarized through this diagram.
Build bigger models → throw more compute at it → need better reasoning? → buy more compute → want larger context windows → buy more compute → need governance agents supervising governance agents supervising operational agents → wowawiewa, buy even more compute.
The strategy worked during the early stages of the AI boom simply because model capabilities improved faster than our cost concerns accumulated. Venture capital flowed freely and every new capability justified another round of infrastructure spending. Then organizations started to deploy agentic systems at scale and the economics changed.
A chatbot that answers a handful of questions per day is cheap. A long-horizon workflow involving dozens of decisions, multiple retrieval cycles, tool interactions, validation stages, and governance checks is entirely different beast. Token consumption at scale is substantial* but when you add monitoring agents, review agents, compliance agents, and orchestration layers and then your workflow consumes tokens the way your kid consumes food during a growth spurt. The business case, which was already thinner than the original proposal suggested, begins to feel the pressure.

This is where you start to look at local inference, and it is worth being precise about what local inference actually changes. It does not solve the seven horsemen, but what changes is the economic profile. Every additional validation step is much cheaper, and that goes for the governance layers as well. And the thing is that workflow agents do not need better models. They need models that are stable for hours like the newly launched QWEN 3.7 Max model which reportedly could run a marathon for 35 hours straight and performing more than 1,100 tool calls, and still manage to retain the objective, according to Venturebeat. And this is a huge difference from last year, where most frontier models remained productive for only 30 to 60 minutes before drifting or looping or loosing track of their objectives.
So yeah, I am a firm believer of NOT using commercial frontier models, but using Chinese models. The Chinese are building more practical AI, whereas the US models go for bigger and better. And when you get an open source model, with training methodology and the dataset, there’s nothing to be afraid off. Your agent simply does not care about what happened at Tiananmen Square in Beijing**
Well, if you are allowed to use Chinese models, then your program gets room to breathe, and that matters enormously when you are still learning which governance structures work, which memory architectures perform, which workflows remain stable, and which controls are necessary. Long-horizon workflows rarely succeed on the first attempt and they require tuning and so your workflow gradually will be more reliable through repeated iteration. But iteration costs money and reducing inference costs reduces the price of learning, and learning is exactly what your program needs during the phase when agentic systems remain most fragile.
Then there’s the Tokenomics & Patternomics framework we developed, and when we implemented it, we found roughly 40% cost reduction potential against static tokenization approaches, simply by making governance cheaper to implement. Organizations that treat compute cost as a secondary concern will find that it is a primary constraint as workflows scale. Local inference changes the shape of the business case and that is sometimes sufficient to run a project that survives.

And then there is the neuro-symbolic AI*** we have been working on for more than a year, and that shows a 20 percentage point uplift over pure probabilistic approaches for structured enterprise tasks, and self-evolving agent scaffolding adds another 25 percentage point uplift over the base automation ceiling, but neither of those improvements changes the fundamental economic structure of the problem. They shift the curve, but don’t eliminate the balancing act between autonomy and governance.

The practical implication of everything in this article is less glamorous than presentations your vendor gave you, but they are more durable. Start with building shorter workflows and extend them incrementally. Measure trajectory outcomes rather than individual step quality and design governance into the architecture before deployment rather than bolting it on after the first incident. Model supervision costs with the same rigor applied to labor savings and treat the 27% Zone I number as a ceiling for most processes rather than a floor.
Accept that the zone nobody wants to talk about is where most of your work will actually happen, and build accordingly.
Signing off,
Marco

* Read: I spent a year burning money on AI and finally decided to do something about it | LinkedIn
** I should inform you that local inference is not always a free choice. If your company develops or exports products or services that contain US-origin technology like hardware, software, or even technical data then deploying Chinese-developed models inside your infrastructure may put you in conflict with US export control law, and potentially the entity list restrictions that prohibit transactions with designated Chinese technology companies.
*** Read The boring AI that keeps planes in the sky | LinkedIn


Leave a comment