Sometimes we build our own tools because the work we do, governed automation, systems that survive audits, real enterprise transformation, needs infrastructure that most vendors have not built and will not until someone else proves it works first.
Here is what we built.
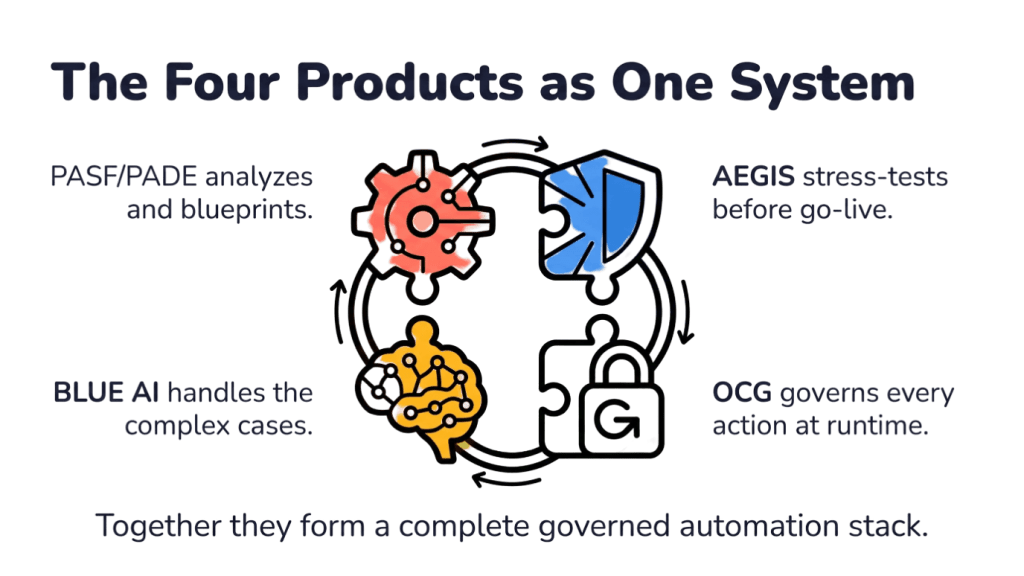
PASF / PADE Process Analyzer
Most automation programs pick the wrong process, build the wrong thing, spend six months on it, and file the results under lessons learned. Based on our research into agentic success patterns, we built a tool that evaluates processes across structure, variability, risk, governance sensitivity, and economic viability. Then we assign the right execution model to each process step, human-only to full multi-agent orchestration, because not every task needs an autonomous agent and pretending otherwise is how budgets disappear.
The output is a blueprint before the spending starts.

AEGIS
AI tends to perform well in demos but poorly in environments with real data, exceptions, and of course people making unexpected decisions. AEGIS simulates those conditions before deployment with poor data quality, policy conflicts, approval bottlenecks, tool outages, semantic drift. It produces a Process Viability Score, a Governance Stress Index, and an HITL ratio. The question is whether the automation holds up when it meets the actual organization. We think that deserves an answer before go-live, not after.

OCG + Neurosymbolic AI
We work ion environments where mistakes have serious consequences. Language models are capable and probabilistic, which means they improvise when uncertain and do not always signal when that is happening. In regulated enterprise processes that is a problem. But with OCG we combine neural intelligence with symbolic control. Language models reason and generate, ontologies define what things mean inside the enterprise and rules constrain what is permitted. Every action passes through formal governance gates before execution. The system can explain what it did and why, and an auditor can verify both.

BLUE AI / GDGA
Zone III is where most enterprise value lives and where most automation approaches reach their limits. Here we find claims operations, regulated case handling, procurement exceptions, complex approvals. A typical LLM does not handle these processes well.
We are currently developing BLUE AI, built on the Governed Dynamic Goal Architecture, which handles this category with goal-oriented execution, persistent case memory, human escalation logic, policy-aware orchestration, and full audit replay. It operates inside explicit boundaries and maintains them over time.

Want to become part of the product team?


