In Greek mythology, there was this guy, Atlas who was condemned to hold up the sky. Not the earth, as the popular version goes, but the celestial sphere itself. The distinction is subtle and mostly irrelevant, except that it captures the exact energy of building a research intelligence platform for enterprise agentic AI that no one really asked for, but I built anyway.
ATLAS is the acronym of Autonomous Task and Long-horizon Agentic Systems, and it is live at multi-step-agents.com, and this is the story of why it exists.

I initially built ATLAS just for myself to help me with the research into long-horizon, multi-step agents that break down in Zone III. Well, Zone III is the point where the impressive AI demos that your vendor made, collide with the brutal reality of long running, complex, and compliance rich workflows. The further an agent moves away from a single prompt and ventures into long-running autonomous execution, the higher the probability of collapse and context fragmentation, tool hallucinations, and what-have-you. I have seen this happening across 177 deployments in 20 sectors, and the pattern is consistent enough to be depressing when you’re running an agentification factory.
But the good thing is that there are lots of researchers working on improving this problem. But the knowledge you need to take this problem seriously was scattered everywhere.
ArXiv papers, half-finished GitHub repos, a few Discord threads here and there from researchers at two in the morning, and a nearly industrial volume of LinkedIn posts from people who automated one spreadsheet and have considered themselves prophets of our synthetic civilization.
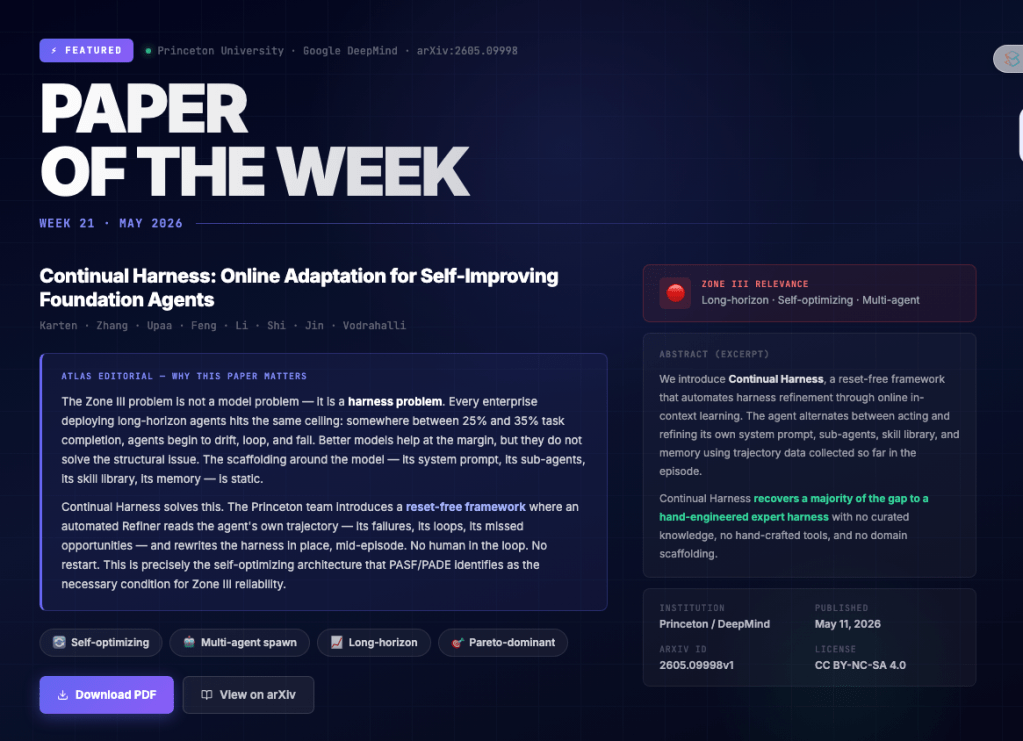
So I built ATLAS to map that territory, totally automated.
It was originally built for myself, because the alternative was trying to stay coherent about the frontier of enterprise agentic AI but the literature doubles every few weeks and the signal-to-noise ratio in blogs approaches the limits of the measurable.
What the platform contains is the following.
The heart of the platform is the automated Research Library, which collects and curates all the latest research on agentic AI, and lets you search the corpus, filter papers by relevance, and see per paper what the claims are, what the methods are, and how it relates to other architectures. Then there’s the Agentic Patterns catalogue that has nearly 770 success patterns organized by memory, orchestration, coordination and risk, and each comes with a description of the problem it solves and the weaknesses it introduces. The Runtime Taxonomy maps a seven-layer architecture model for autonomous systems (Tool Execution through Recovery and Audit) and connects each layer to its governance implications and failure risks. The Failure Intelligence database catalogues critical, high and medium severity failure modes with symptoms, root causes and causal relationships between patterns, including an interactive causal graph. A Knowledge Graph that matches papers to others, and the same goes for patterns. The Benchmark Observatory tracks eight benchmarks, a model leaderboard covering GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro and others, and a Blind Spots section that documents the gaps in current evaluation methods. There is also an API for connecting your own agent pipeline.
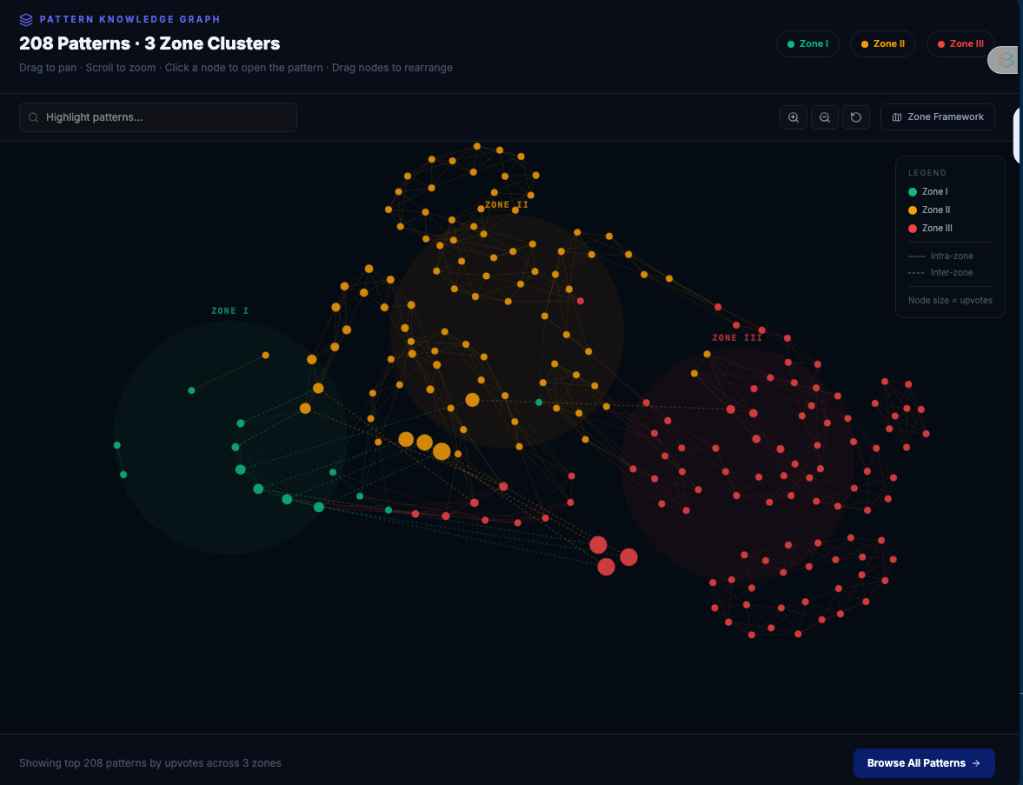
And if you don’t like searching through a bunch of papers, and you’d rather read a book full of patterns including an exegesis of 300+ papers, then you can download the ATLAS Book of Knowledge.
Everything on ATLAS runs fully automated. Agents scour sources, ingest them, triages the content, comments on papers that are relevant, categorizes them and so on. Even the ATLAS B.O.K. is generated every month.
The reason I am opening it now is that I kept running into people hitting the same walls, and trying to rebuild the same knowledge that already existed somewhere and was simply not findable, and ATLAS is for those people. For the round pegs in the square holes.. nah.. I mean, for the enterprise AI builders who are way past the demo phase and work for an executive who has built their business case on Zone III (as always). And now, you find yourself now figuring out why production behaves differently. It is also for the governance people who want to know which failure modes to document before the auditor does it for them.
It’s actually for anyone working on the question of how to build an autonomous system reliable enough to be trusted with something that actually matters.
Most of the content is publicly accessible without an account, but participating in community discussions (and the AI feature*) requires registration.
Some sections like benchmark intelligence, parts of the governance documentation, are still being filled in, because the field moves faster than any single platform and I am one person with a dachshund, lots of research backlog, and a day job. When you first access the platform, there’s a guided tour, but knowing you, there’s also an X in the right upper corner.

Anyways . . .
Atlas carried the sky because he had no choice. I built this because the alternative was continuing to drown in a field that updates itself faster than the people working in it.
Give it a shot!
Signing off,
Marco
* At this moment the AI is in closed Alpha mode. This will be a “bring your own token” model.
Oh… if you find a bug, please drop me a DM, and I’ll invite you to the AI Alpha!
Eigenvector builds Agentification factories at scale, for production environments that actually have to pay-off, and Eigenvector Research occasionally publishes papers about why this is harder than the demos suggest.
👉 Think a friend would enjoy this too? Share the newsletter and let them join the conversation. LinkedIn, Google and the AI engines appreciates your likes by making my articles available to more readers.

Leave a comment