Enterprise AI budgets are disappearing without delivering results
The most expensive sentence in enterprise technology is “we can start the deployment next quarter” and I have heard it so many times that I hear it in my sleep.
Sigh.
Enterprise AI is eating budgets at a speed that would make an ex 1996 eCommerce bubble entrepreneur shed a single dignified tear. Because in a growing number of organizations, the business results from AI are so thin you need a microscope to find them. But the compute bills are real though, and even if you don’t play along with the tokenmaxing trend, your annual contract with the inference provider and your Azure AI Foundry or WatsonX, Vertex, Bedrock or Einstein is very, very real. The transformation, though, the actual measurable shift in how the company operates, well, that part of the business case is arriving fashionably late, somewhere between the third roadmap revision and the executive who championed the whole thing and is now being moved to a different role without a press release.
I have watched this pattern repeat itself with a reliability that would be impressive if it were not so expensive. Here’s how these things usually go . . .

A company announces their AI-transformation initiative. A steering committee is formed and a vendor gets selected. Then the pilots are being selected – usually not based on potential value, but simply because an executive has a “gut feeling” and who are you to question that. The pilots are then presented with a Powerpoint and an Excel sheet that truly show promising numbers. But those numbers are usually real in the same way that a movie trailer is a real depiction of the actual movie, they’re technically accurate and of course carefully edited, yet they’re bearing almost no resemblance to what you actually get when you sit down and commit. Then the rollout happens and your steerco sees the costs scale and somewhere in the middle of all of it, people in operations are still manually copying data between two systems because the agent could not figure out what to do when the field was empty, or worse, it decided to create a line item that shouldn’t even exist.
The reason this keeps happening is not so much a fault of the technology, the models are genuinely impressive, though we’re still plagued now and then with the occasional hallucination, but the reason this keeps happening is that organizations are deploying intelligence on top of ignorance.
Yes, agentification teams are feeding AI agents into workflows that nobody has actually understood at a level that would make automation remotely safe. They are building skyscrapers on foundations made of assumptions and gut feeling and then act surprised when the orchestration starts to shake.
And in this here blog, I am going to explain what is actually going wrong here, and why process mining which is one of the most unglamorous tools in the enterprise software cabinet, is about to become the most important piece in your arsenal that serious organization should invest in for a successful AI future.

The gap between what companies think their processes are and what they actually are
Most companies that prefer predictability over the thrill of a six-figure invoice arriving without a matching business outcome, have defined their processes up to a certain level.
A business activity has a process. It also has a name describing the activity, and it has an owner. If you’re ‘lucky’, it also has a BPMN diagram, lovingly produced by a consultant in 2019 which was printed once for a workshop, but never opened again. And when you’re really, really lucky, it also has a Level-5 Standard Operating Procedure document or a Work Instruction living in a SharePoint folder whose URL nobody can remember, last updated by someone who no longer works there. And usually it has a ‘subject matter expert’ who, when asked how the process works, says with complete confidence, “oh I know exactly how that works” and then describes something that bears a vague resemblance to what actually happens but is missing about forty percent of the steps, all of the exceptions, and the entire shadow system that three people in operations built in Excel because the official system could not handle edge cases.
Sounds familiar, huh?
Well, my smart friend, this is not something you only come across in badly managed companies. I’ve found this to be the story about all companies, even the ones boasting an ISO certification and a consulting bill large enough to fund a small space program. The gap between the documented process and the lived process is one of the most consistent and under appreciated facts of organizational life, and it exists everywhere, from manufacturing to financial services, yes, in every sector that has ever appointed a ‘business process owner’ to draw a flowchart and then gone back to doing things the way he always did.
Yeah.
The real process does not live in the documentation. But where it lives is in the system logs that show how long something actually sat in a queue before anyone touched it, and also in the rework loops that appear when a handoff goes wrong or in the escalations that happen because the official decision criteria are ambiguous and especially in the human workarounds that people have built up over years of navigating systems that do not quite talk to each other.
Process mining reads those logs.
It reconstructs what actually happens over time. The gap it reveals is usually shocking to the people involved, and I mean that in a psychological sense, the shock you feel when you see your X-ray and then you realize the bone has been broken for years and you simply learned to walk around it.
IBM did some research on automation failures, and they wrote it down in a piece called “Five reasons why business automation initiatives fail and how to avoid them”. In it, they found that organizations routinely automate broken or poorly executed processes, meaning they spend significant money making the wrong thing happen faster.
And I have a feeling this is not the first time you’ve hear this particular story, and if none of this rings a bell, you are either very new to enterprise process automation, or you’re very good at forgetting (which can be a bliss in corporate politics).
That sentence should be on a poster hovering over every AI program’s ping-pong table, but instead it is buried in a Powerpoint deck that of course no one reads because all-of-them are busy attending the weekly agent demo.
And task mining adds the human layer.
Process mining tells you what the systems recorded but it doesn’t tell you what the person did when the system stopped being useful to him, which is usually somewhere around step four of a process. It captures screen-level behavior, the workarounds people try out to beat the system, the Excel files they use for quick calculations and the tab switching that nobody documented because no one even thought of it as a process, even though it has been running reliably for three years on someone’s second monitor.
U-huh – this is the level of knowledge about a process you need to know before you start automating it with AI. As if you didn’t have enough to worry about. . . I know, it sucks.

Agentic AI demands a level of process detail that most organizations cannot provide
With a bit of luck you’ve had some experience with process automation before when you tried RPA-ing a process. What I have always appreciated about traditional RPA-based automation, is that it was built to tolerate a certain level of process disorder without immediately becoming a liability.
A traditional RPA script is essentially akin a literal-minded employee who does exactly what he is told, every time and in exactly the same order, but he fails when reality does not match his instructions. He is rigid, but that rigidity is a feature when your process is messy, because at least you know immediately when something goes wrong.
Yes, my friend, looking back at RPA, the thing that made us yearn for AI is actually the thing that I miss most. Because an AI agent is a fundamentally different kind of beast, and this difference matters enormously for what I am about to argue.
An AI agent is not following a deterministic script.
It is making decisions, based on context, and choosing between possible actions. It can handle ambiguity and determine when to proceed or when to escalate, and doing all of this continuously across a workflow that may span multiple systems, departments or even multiple days. But it also needs to know what a normal state looks like so it can recognize an abnormal one, and it has to be shown what a valid transition is so it can detect an invalid one, and when it encounters something’s off, it has to have clear escalation logic. And in my program, it is also trained to optimize cost boundaries, because an agent that keeps retrying an API call that will never succeed is actively burning our token budget while failing.
All of these requirements need one thing that most organizations do not have, which is an operationally honest understanding of how their processes actually work.
Without that foundation, what you get is what I’m calling “autonomous employees with no onboarding and a company credit card”. They are autonomous, yes, and they’re also profoundly confused about what they are supposed to be doing, because somebody gave them a map from 2019.
Last year in June, our hype-cycling buddies at Gartner estimated in their press release† that more than forty percent of agentic AI projects will be cancelled before the end of 2027, with escalating costs, unclear business value, and insufficient governance cited as the primary reasons. I would argue that all three of those reasons point to the same underlying cause, which is that organizations are deploying agents into process environments they do not understand, and discovering the cost of that ignorance at scale.

† Press release titled “Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027”
Process mining gives enterprise AI the operational foundation it needs
Process mining tools, and here I mean platforms like Celonis, UiPath Process Mining, SAP Signavio, and a few others, they do something that sounds simple but it turns out to be profoundly valuable. They read your event logs and show you what is actually happening in your operations. And if you have ever seen a detailed process map they produce, you know what I mean
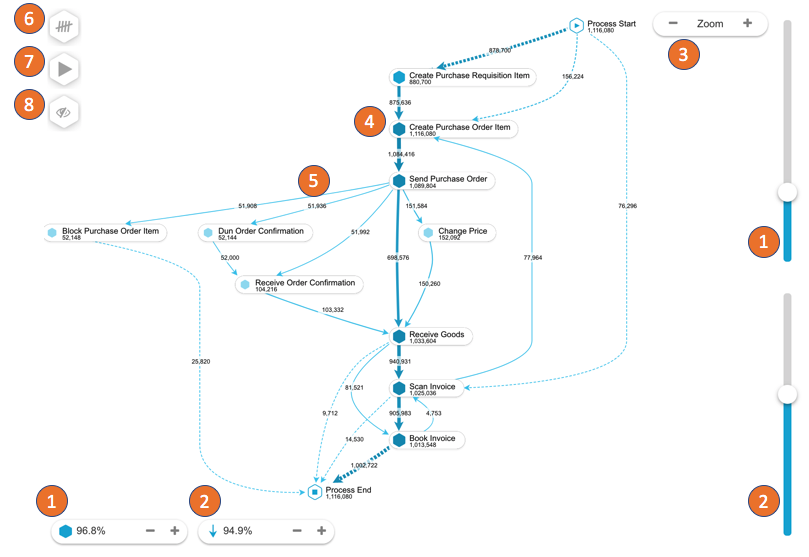
These tools show you where the bottlenecks are, not where you think they are, but where the data shows time actually accumulates and it shows you which approval steps are adding delay without adding value, and then you see the variant explosion, meaning the number of different paths a single process type actually takes in practice, and that always turns out to be far larger than the number of paths anyone designed on paper or in Aris. A process that was designed with three variants often has forty in practice, and each of those variants represents a different set of things no one thought to write down that an AI agent will eventually have to navigate
They also do something that is particularly valuable for enterprise AI planning and that is because they identify the automation candidates that are worth pursuing.

In practice there are four types of processes out there that you come across in your AI projects, and I have described them a couple of times before, so for the regular readers, you can skip this part.
Zone I is highly structured, low-risk, and repetitive. This is the stuff that gets you the eyeballs and the o’s and the a’s when you’re trying to sell your program. The honest problem is that most agentic automations in this zone cannot be called ‘transformational’ with a straight face. When you’re targeting these “quick wins”, you’re looking at what I call ‘point solutions’. Stuff like triaging email for data, and filling rows in an Excel spreadsheet or scanning an invoice live in this zone, and of all the agentic implementations we analyzed, we saw that 27% of enterprise process steps actually land here and the documented success rate for zone I deployments is 71%.
Zone II covers 17% of enterprise process steps and has a success rate of 52%. That sounds acceptable at first glance, until you remember that the other 48% generates cleanup work that never appears in the dashboard that your steering committee sees. These processes have a clear structure most of the time but they fall apart on the edges, because it has a missing field, or an undocumented exception that someone always handled manually, you know, edge cases and variants. This is however, the first zone that starts with humans-in-the-loop.

21% of enterprise process steps fall into Zone III and they have a success rate of a mere 31%. And this, my curious friend, is the number that should be printed on every agent deployment proposal in a font large enough to read without glasses. These are processes that are structured enough to be automatable in principle but they’re rich in exceptions, compliance and risk. So rich, that deterministic automation like RPA has always broken down on them. This is, however, where you’ll get real productivity gains, but it’s also the place where the token cost profile is highest, because ambiguity costs compute and Zone III processes are full of it. Without process mining, an agent in Zone III is working from a process description that was written by someone who thought they knew how things worked. But that turned out to be wrong. Hence the 31%.
But these are exactly the processes where modern AI agents can create real value, and process mining is the tool that surfaces them with evidence rather than intuition.
Celonis has articulated this directly in describing what they call process intelligence, the idea that AI agents need business context derived from actual process data to function effectively in enterprise environments and without that context, an agent is operating on assumptions, and assumptions in a production environment are kinda expensive.
Zone IV covers 12% of the cases we documented carries a success rate of 8%. Yeah. This is a number you’ll never hear vendors pitch. These are the high-stakes, high-ambiguity, low-structurability, and contraindicated for autonomous handling under current conditions. The failure cases for Zone IV deployments share one characteristic, the organizations involved had convinced themselves they were in Zone II, usually because someone with a financial interest in the project told them so. When someone claims that agentic AI is already capable of automating this zone, I simply ask them if they’re ok with flying in an airplane flown by ChatGPT.
Indeed.

The compounding cost of deploying agents without process intelligence
I want to spend some time on the mechanics of what goes wrong, because I think the failure mode is less obvious than it appears.
When you deploy AI agents into an unmapped process, the first thing that happens is that the agents perform reasonably well on the uncomplicated cases that were implicitly the ones everyone was thinking about when they designed the system. These cases is what you have in mind when generating the numbers in the pilot deck, but the thing is they represent maybe thirty percent of the actual volume.
The other seventy percent is all about compounding.
An agent that encounters a case it was not prepared for keeps trying, consuming tokens, making API calls, attempting variations, sometimes creating side effects in connected systems, and either eventually giving up or eventually producing an output that is technically a response but not actually a correct one.
Every one of those failed attempts costs money and every incorrect output creates downstream work and cases that requires human intervention is a moment that generated AI cost without delivering AI value, and in a high-volume environment, these cases accumulate fast.
The hidden manual cleanup work is perhaps the most insidious consequence, because it is invisible to the metrics that get reported upward. The agent completed the task, in the sense that the workflow state changed. The fact that someone in operations spent forty minutes correcting what the agent did does not appear in the dashboard that shows the steering committee how well the AI program is performing. The ROI calculations look fine, the operations team is drowning.
IBM has documented this pattern extensively in their paper with the title, “Five reasons why business automation initiatives fail and how to avoid them” and in it, they’re saying that the organizations who are most likely to see returns from automation are the ones that invested in understanding their processes before deploying technology into them. The ones that skipped that step tend to end up with an expensive lesson.
Token costs are the most visible line item in an enterprise AI budget, and in this context, they are a symptom for all the exception handling, and the cases where the agent did not have enough context to act confidently and had to work harder to produce an output. This finding is what I used in the Poundwise Tokenomics and Rountrip Value Governance research papers†.
† Links to the papers in the comments.
Building the stack, mining, simulation, deployment and governance in the right order
The organizations that are going to get this right treat enterprise AI as an operating model problem before they treat it as a technology problem, and the operating model that works looks something like this.
It begins with process mining as a diagnostic layer and not a one-time exercise but a continuous capability that reads event logs across the enterprise and produces an ongoing, evidence-based picture of what is actually happening in operations. This is the foundation. Everything else is built on top of it.
The second layer is simulation‡, and this is the step that almost everyone skips because it feels slow and because the vendor is waiting to start the deployment and because there is a board presentation in six weeks.
Simulation means taking the process intelligence you have gathered and modeling what happens when you introduce an agent into specific steps, predicting impact on throughput, cost, quality, and exception rates before you commit to a production environment. Apromore‡ and similar tools have invested significantly in this capability precisely because the cost of getting it wrong in production is so much higher than the cost of getting it wrong in a simulation.
The third layer is all about controlled deployment and in it, you have a rollout that is staged and reversible, with clear criteria for what success looks like, clear triggers for intervention, and humans in the loop for the exception categories that the simulation identified as high-risk.
And when you have deployed, you get to the fourth layer, the runtime governance of the process through process mining. Yes, this means the process mining capability does not go away after deployment. It only shifts into monitoring mode where it is continuously comparing what the agents are actually doing against what they were designed to do, and they’re flagging deviations and measuring recognized value. I’m doing this at this moment with Celonis to measure Net Program Value†
This stack is not glamorous but it generates something valuable in the sense that it proves that your program actually works at scale and over time, without having to upscale the operations team that has to clean up after it.
‡ Read the AEGIS – Agentic Enterprise Governance and Intelligence Simulator – paper in the comments
† Read the Roundtrip Value Governance for Agentic Process Automation paper.
What executives need to do before the next vendor pitch lands in their inbox
The first thing you need to do if you’re an executive is that you need to stop buying technology before buying understanding.
Yes, I agree, this sentence deserves to be on a motivational poster near the ping-pong table.
Process mining is not a prerequisite that appears in consultancy pitches because consultants want to build agents, but it is a prerequisite nonetheless, and for the organizations that skip it, the audit will be along shortly.
The second thing you need to do is to fix the handoffs before automating around them. I mean things like double data entry or manual transfers between systems or multiple approvals. They are structural failures that an AI agent will either replicate or get stuck on, and either outcome costs money.
As a ballpark figure, an hour spent fixing a handoff before deployment is worth roughly ten hours of token spend trying to navigate it afterward.
Also treat event logs as a strategic asset. This means you invest in the infrastructure to collect the process telemetry and the tooling to analyze them, but also the organizational discipline to act on what they show. Most enterprises are sitting on data that would tell them exactly where their highest-value automation opportunities are, and they are not reading it, because nobody put a dashboard on it and nobody made it someone’s job to care.

Measure recognized value rather than productivity proxies. Tasks completed, time saved, FTEs theoretically freed, these metrics are easy to produce, though they might be what your management wants to see, but they’re almost useless for understanding if your AI program is creating real business impact. The metrics that matter are cycle time reduction in specific processes, error rate changes in specific outputs, cost per transaction in specific workflows, and ultimately the effect on revenue, margin, and risk. If your AI program cannot produce those numbers, you should design them in.
Last thing is that you stop letting the technology conversation happen separately from the operations conversation. Enterprise AI is not an IT project with a business sponsor but a fundamental change to how the organization operates, and it requires people who understand operations, processes, exceptions, and edge cases to be in the room from the beginning.
Process mining is the discipline that makes these conversation possible on beforehand, because it gives everyone in the room the same evidence-based picture of how the organization actually works, rather than a collection of competing opinions about how it should work.
Process mining was never the exciting part. It was always the necessary part. The organizations that figure that out before the invoice arrives will be the ones still running AI programs in three years. The rest will have a very interesting case study and a much smaller budget.
Signing off,
Marco
Eigenvector builds Agentification factories at scale, for production environments that actually have to pay-off, and Eigenvector Research occasionally publishes papers about why this is harder than the demos suggest.
👉 Think a friend would enjoy this too? Share the newsletter and let them join the conversation. LinkedIn, Google and the AI engines appreciates your likes by making my articles available to more readers.

Leave a comment